A Closer Look at the Process of Building Machine Learning Models for Intelligent Asset Management
The advent of digital automation systems coupled with advances in Big Data, Artificial Intelligence (AI) and the Industrial Internet of Things (IIoT) technologies makes it possible for plant operators to collect, consolidate and analyse very large amounts of data about their assets. In this context, most Intelligent Asset Management (IAM) consultants and practitioners agree that the future of asset management and enterprise maintenance is data-driven. During the next few years, most decisions about industrial assets will be taken following a process of collecting and analysing data about the present and future state of the asset. Furthermore, plant operators and service providers will increasingly attempt to derive predictive insights about their assets, as a means of optimizing processes like maintenance and repairs.
State of the art asset management platforms such as SAP Intelligent Asset Management come with a host of utilities and functionalities that facilitate the challenging tasks of collecting and consolidating data from multiple, distributed and heterogeneous sources. Moreover, they offer tools for designing and executing advanced analytics algorithms, such as predictive analytics, based on deep neural network techniques. Even though these tools lower development and integration times, the task of extracting data-driven knowledge about the current and future condition of an asset remains extremely challenging. Training software agents to predict the evolution of an asset’s state is not merely a task of injecting a dataset in a data mining tool. Rather it requires expert knowledge that combines insights from business operations with expertise on the statistical properties of different datasets.
Consultants and data mining experts that design, build and deploy intelligent, data-driven asset management solutions are nowadays offered a wealth of models for predictive analytics with varying performances and levels of robustness on different datasets. Likewise, the business objectives of each project are different and impose unique requirements about the data points that are needed and the machine learning techniques that have to be employed. In order to cope with the challenges of matching data mining techniques with business objectives, enterprises must undertake two main steps: First to assemble a competent and multi-disciplinary team of experts, and second to follow disciplined and well-structured data mining methodologies that will save them time and effort.
Building the Data Mining Team: A Challenging Exercise
One of the main challenges of machine learning and data mining projects for Intelligent Asset Management is the establishment of a multi-disciplinary team of experts and consultants. The team should have adequate expertise in the following areas:
- Big Data Infrastructures and Databases: This expertise is needed in order to manage the large volumes data stored for use by the asset management applications. Expertise on Big Data and databases (e.g., SQL and noSQL databases) is required in order to access the different datasets that will be analysed in the scope of the IAM application development. Therefore, database experts should be competent in managing large datasets, as well as in programming database applications based on popular languages for Big Data such as Python, R and Java.
- Data Scientists and Machine Learning Experts: Data scientists process Big Data in order to extract knowledge from them. They are likely to employ statistics and/or machine learning techniques in order to derive insights about the status of the assets, based on historical datasets. Data scientists have typically IT expertise as well, especially in the areas of databases and database management systems.
- System Integration Experts: A data mining team should also include software developers and system integration experts that will be able to develop applications over middleware platforms for IAM, such as the SAP Cloud platform. Software developers should be capable of designing and developing user interfaces (e.g., based SAP UI5), as well as web applications running on the SAP Cloud Platform based on technologies like JavaScript and Java. Moreover, system integration experts should be proficient in modern technologies for DevOps development and IoT/Big Data integration, including technologies like microservices, device connectivity and business information systems integration.
- Business Domain Experts: The team should also include asset management experts in the industrial sector of the IAM project. Such experts must possess domain knowledge about the operational and functional characteristics of the assets (e.g., machines, tools and other forms of industrial equipment). Domain experts will formulate business problems in ways understandable by data scientists. Furthermore, they will audit the validity of the knowledge extracted by data mining techniques against known rules and patterns of knowledge. In this way, domain experts will help the team to identify potentially biased or spurious patterns observed in the data. Likewise, they will shift the attention of the team towards patterns that are interesting, yet do not contradict established knowledge and rules of the business domain.
- IAM Consultants: Intelligent Asset Management consultants will contribute knowledge and skills on the Asset Management platform used, such as SAP Intelligent Asset Management. Their role is focused on translating business requirements to IAM workflows on the Asset Management software used. In this way, IAM consultants will enable the rest of the team to take advantage of the value-added features of the asset management platform towards optimizing the project’s value for money.
In several cases, a single person may play more than one of the above roles. For example, there are machine learning and AI experts that are proficient in data management and databases. Likewise, several IAM consultants combine asset management knowledge with system integration expertise. Note also that as IAM projects get more complex, additional expertise might be required, such as expertise in visualizing very large datasets and predictive insights for the assets. Visualization might take simple forms like Big Data dashboards, yet it can be also more sophisticated based on the employment of animations and ergonomic cyber-representations of assets’ data (e.g., Virtual Reality (VR) visualizations).
Bringing together all the above experts can be very challenging for various reasons. First, there is a talent gap in new Industry 4.0 technologies, including data science and machine learning. Second there is also a shortage of experienced and competent consultants in products and services for intelligent asset management. Last there is also scarcity of business domain experts. The latter tend to be very busy in their everyday tasks (e.g., maintenance and field service operations) and enterprises are reluctant to engage them in new digital automation and smart asset management projects.
Understanding Standards Based Data Mining Processes
Once established, data mining teams must engage in iterative processes that discover, test and validate alternative models for knowledge extraction from the data. There are many different methodologies that can drive the work of a data mining and knowledge extraction team. One of the most popular methodologies is CRISP-DM, which stands for Cross-Industry Standard Process for Data Mining. CRISP-DM is a five-step process that describes a structured approach to planning and executing a knowledge discovery and data mining project. It is not specific to Intelligent Asset Management. Rather it is applicable to different types of projects that involve knowledge extraction from very large datasets. In the following paragraphs, we present CRISP-DM as a methodological instrument for structuring the work of a data mining team. In practice, the steps that are described in the following paragraphs need not be followed faithfully. Consultants can take the freedom to slightly alter the different steps of the process and the activities that they comprise in order to better customize the methodology to the peculiar needs of their project. Hence, CRISP-DM is practically an educational device, rather than a rigorous standard that should be followed without deviations.
Step 1: Business Understanding
The first step of the CRISP-DM process focuses on describing the objectives of the IAM project in business terms. Moreover, it outlines related success criteria and indicators that would signal the accomplishment of the business objectives. These objectives are also translated to more technical machine learning and data mining goals (i.e., technical targets that if met will signal the business success of the project). As a prominent example, a business improvement goal for asset management might boil down to success indicators like:
- Predicting the RUL (Remaining Useful Life) for an asset, as a means of optimizing the asset’s maintenance schedule.
- Flagging irregular or anomalous behaviour, as a means of detecting defect patterns or the start of an asset’s degradation period.
- Producing recommendations about service or maintenance, in order to mitigate quality problems following the identification of a defect pattern.
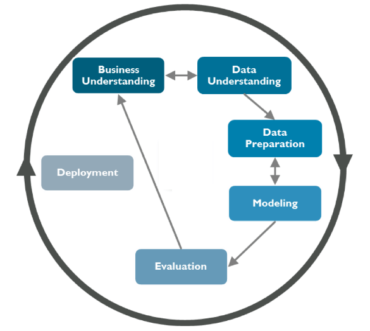
In the scope of the business understanding step, an initial project plan is also produced, including information about the activities to be undertaken, the resources required, the expected outputs and the dependencies between different tasks. Likewise, an initial assessment of existing hardware (e.g., computing platforms and cloud resources), software (e.g., data mining platforms and tools), data (i.e., industrial and asset-related datasets) and human resources (e.g., consultants, programmers, data scientists, domain experts) is performed, in order to document the resources available for accomplishing the project’s objectives. Overall, the first step of the CRISP-DM methodology establishes the asset management problem at hand and inventories the resources available to confront it.
Step 2: Data Understanding
There is no machine learning and AI without the proper data assets. Therefore, the second step of the CRISP-DM methodology is focused on understanding the available data, as a means of deciding whether they suffice for the business problem at hand. In this direction the data scientists of the team will have to inspect and visualize the available data assets, in order to understand their wealth, breadth and their statistical properties. To this end, they may load the data in some data mining tool, while they may also endeavour to visualize them in different charts.
The data understanding step involves reviewing the statistical distributions of some key attributes (e.g., readings of sensors associated with an asset), as well as the identification of some prominent correlations between different attributes. Such statistical insights will assist data scientists in defining candidate machine learning models such as models that could successfully derive predictive insights about specific parameters. For example, they could drive data scientists in defining models that could successfully predict quality control values that signify defective parts of a product. In the scope of this process, data scientists may have to consult domain experts, in order to understand which attributes of a production process and a quality control process can be used as predictors of the future status of the asset.
The data understanding process will also provide useful insights regarding the volume and the quality of the datasets. For example, datasets with many missing values might be inappropriate for attacking the business objectives at hand. Likewise, a dataset with very few failure or defect-related incidents won’t suffice for implanting credible classifiers about the current and/or future state of the asset. Therefore, there is always a possibility of deducing that the available data assets are not adequate or appropriate for answering the target business questions. In such cases, the team might need to revisit the business understanding step in order to formulate the business problems differently (i.e., in a way that can be addressed based on the available data points).
Step 3: Data Preparation
The data preparation step starts with the selection of the data that should be analysed in order to address the business problem at hand. Following the data understanding phase, the team should have identified the parts of the datasets that are relevant for the project. The selection of the data will enable programmers and system integrators to implement methods for accessing the data from the different systems and sources where they reside. Platforms like SAP’s IAM provide many utilities and support for these tasks. Following the selection of the data, this step undertakes also the task of cleaning the data as a means of improving their quality.
Apart from data cleansing, the data preparation step involves the pre-processing of the selected data in order to become formatted according to the input required by the models to be tested. As part of this process, some new (“derived”) attributes will have to be calculated, while other attributes will have to be transformed into different formats. For instance, some algorithms may require as input the aggregate number of failure instances, which can be derived based on a simple calculation of failure occurrences in the dataset. As another example, dates, times, currencies and other attributes might have to be transformed from one format to another.
Except for operations on single datasets, the data preparation phase includes also complex data integration and data consolidation operations across multiple interrelated datasets. For example, failure information for a product can be found in an ERP system and in a Computerized Maintenance Management System (CMMS). During data preparation, such failure information can be consolidated in a new dataset, prior to clustering different products based on their failure information.
Step 4: Modelling
This phase is the gist of the machine learning process. It entails the selection of the machine learning model to be used for deriving knowledge from the existing datasets. Different models can be selected and used depending on the business requirements and their associated data mining requirements. For example:
- Regression models can provide a relatively simple way for predicting RUL.
- Different types of classifiers (e.g., decision trees, Bayesian techniques) can be used to classify assets or products as OK or not OK (NOK).
- Unsupervised machine learning techniques (such as clustering) can be used to identify potential abnormal behaviours for an asset.
Several problems might also require the deployment of more complex models such as deep neural networks, which can be much more efficient in detecting complex degradation patterns of an asset’s behaviour, yet they need to be trained with high volume datasets. As a prominent example, Long Short Term Memory (LSTM) networks are commonly used for predictive maintenance problems, given that they are extremely efficient in learning to derive predictive insights based on large historic sequences of failure examples.
The testing and validation of each different model involves training the model based on a subset of the available data, and testing it on another subset of the data. The test datasets must be different from the datasets used for the training, otherwise the modelling process is not credible. As part of the testing process, the team gets insights on the accuracy of the model, through evaluating parameters like classification error rates or the precision of the model (i.e., the fraction of relevant failure instances among the total retrieved instances).
In the scope of the modelling process, data scientists may have to collaborate with domain experts in order to discuss their findings with respect to the accuracy and appropriateness of each model. Domain experts are likely to contribute domain insights about the actual attributes that must be taken into account during the model building process (e.g., which attributes of a dataset are representative for an asset’s state). Moreover, domain experts can help data scientists in developing generalized models that are likely to work in the long term, rather than more specific models that only work for the datasets at hand. Note also that as different models are tested, there might be a need for revisiting the data preparation phase, in order to prepare new datasets that are appropriate for the model under test.
Step 5: Evaluation
The final step of the CRISP-DM process is focused on the business-level evaluation of the derived model(s). As part of this step, each model is evaluated against the business objectives of the project, rather than merely on its efficiency over the test datasets. In the scope of the business-level evaluation, parameters like the simplicity, the training speed, the classification speed and the explainability of the model might be taken it account. Likewise, parameters like timing and budget constraints will be considered as well. The final outcome of the evaluation step might be the actual deployment and use of a machine learning model in production. The latter will require additional software integration work, as well as implementation of additional features like user interfaces and visualization dashboards. However, the evaluation step might also lead to the quest for a new model (i.e., to the modelling phase) or even to the quest of an alternate business problem (i.e., back to the business understanding phase). The evaluation step will therefore determine the next step of the Intelligence Asset Management project.
Other Data Mining Processes
As already outlined, CRISP-DM is an educational device rather than a process that has to be followed without deviations. Its iterative nature facilitates the testing of alternative options and solutions regarding machine learning models for the management of your assets. Nevertheless, CRISP-DM is not the only process for data mining. There are other processes, which however bear a lot of similarities to CRISP-DM. As a prominent example, the KDD (Knowledge Discovery in Databases) process for data mining includes similar steps to CRISP-DM, including:
- The development of an initial understanding of the application at hand, including its business objectives.
- The creation of a target dataset that will serve as a basis for the knowledge discovery.
- The cleaning and pre-processing of the dataset, including for example removal of noise and handling of missing data.
- The selection of a data mining and machine learning method and its training based on the available data.
- The searching, discovery, interpretation and evaluation of knowledge patterns on the dataset, based on the selected machine learning methods.
KDD is also an iterative process and allow for the testing and validation of alternative models.






